

CUDA를 사용해서 gpu연산처리를 사용할 때, version 혹은 dependency 문제로 인하여 여러가지 Error와 만나게 될 수 있다.
GPU를 돌리던 중, “cuDNN error: CUDNN_STATUS_INTERNAL_ERROR ~ “ 라는 error message를 보게 되었고, stack overflow 등에서 아무리 해결방법을 찾아봐도 뚜렷하게 해결한 사람이 보이지 않았다.
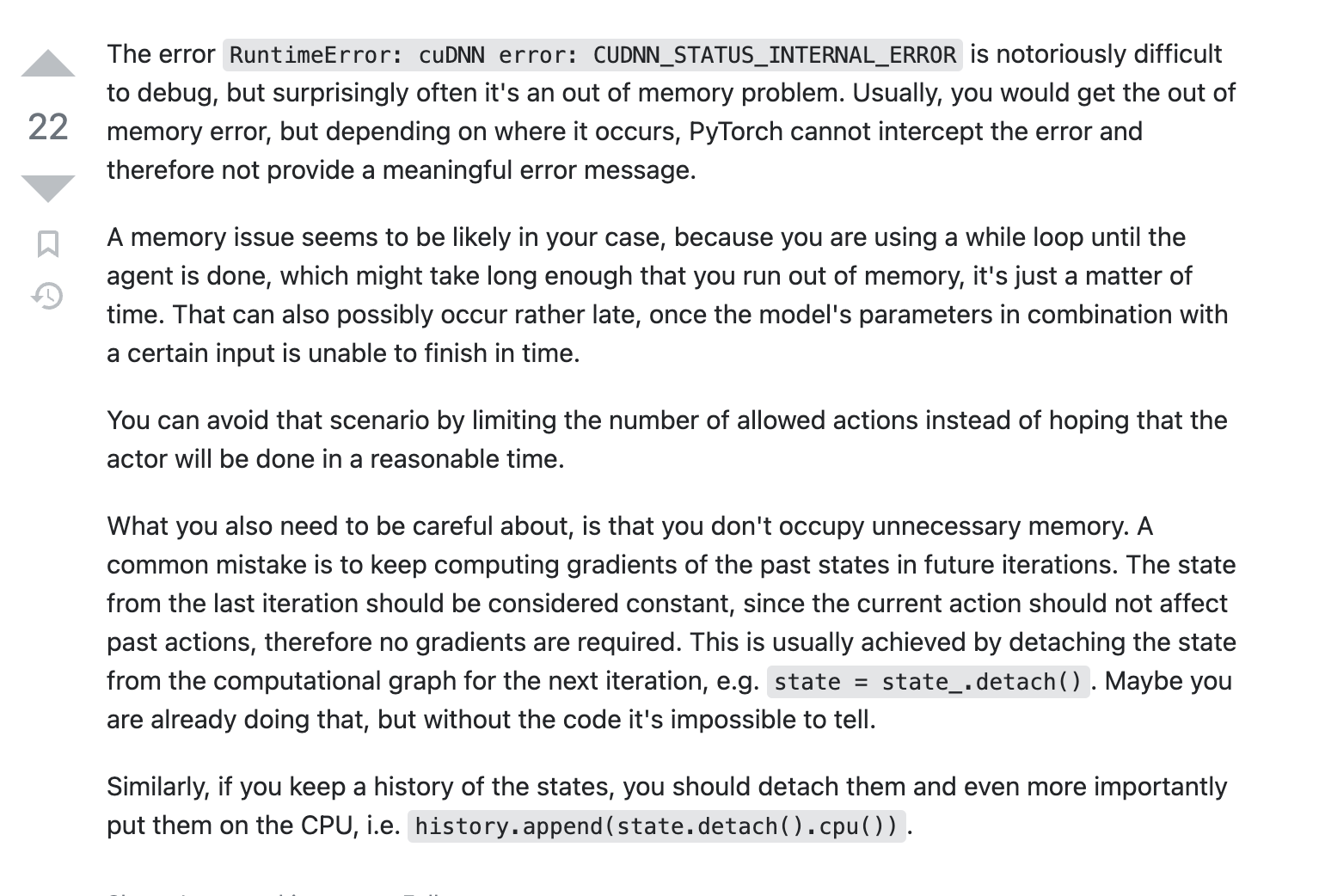
한 마디로 debugging으로 해결하기에는 불가능에 가깝다는 소리..
나의 경우는 nvidia-smi로 메모리 사용량을 확인해봐도 별다른 문제가 없었고, error message에 “torch.backends.cuda.matmul.allow_tf32=False” 라고 되어 있어서 이것이 문제인 줄 알고 cuDNN 버전 확인 및 재설치를 해보았지만 달라지는 것이 없었다.
그러다가..?!
Train 시킬 dataframe의 label값을 label encoder 시켜주니 아무 문제없이 training이 진행되었다..
원래 label 값도 수치형 데이터 ex) actionOption -> 121, 739, 82, etc.. 여서 따로 labeling을 해줄 필요가 없다고 생각했는데, label 값이 가장 큰 값까지 연속적으로 모두 있다고 인식되어서 문제가 생겼던 것 같다.
수치형 데이터도 왠만하면 training 전에 labeling 하는 것이 좋을 것 같다.
아직 의문인 것은 내부적으로 tensor연산이 진행되는 과정 중 왜 cuDNN에서 저런 error message를 출력했는지, tf32관련해서 무엇이 문제인지는 알지 못했다.
관련된 insight를 가진 사람은 댓글로 알려주길 바란다..
어쨌든 나와 같은 error로 고생하고 있는 사람이 혹시나 있다면, df target값의 labeling이 잘 되어서 중간에 문제는 없는지 확인도 한번 해보길 바란다..!
Comments